Logan Bolton
Undergraduate Researcher at Auburn University interested in AI/ML and Computer Vision

About Me

I am a Computer Science major with a minor in Statistics at Auburn University, where I will graduate in Spring 2026. I have experience with Python, PyTorch, SQL, JavaScript, HTML/CSS and more.
I am currently seeking full-time opportunities for AI/ML related roles after graduation.
View ResumeSelected Papers
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
Native multi-modal image-editing models like GPT-4o and Gemini have shown an impressive ability to edit images through natural language prompts. This paper examines the strengths and weaknesses of these models when pitted against one-to-one matchups against human editors.

Vision Language Models are Blind
This paper shows the limitations of VLMs, such as GPT-4o, in extremely simple, abstract vision
tasks. Despite their high scores on multimodal benchmarks, these models often fail on very basic
cases.
This research has been featured by OpenAI, TechCrunch, and Ars Technica.


Experience
Undergraduate AI Researcher
Explainable AI Lab - Auburn UniversityI am an Undergraduate Researcher in Dr. Anh Nguyen's Explainable AI lab. Since joining in July
2024, I have co-authored three different papers on understanding the strengths and weaknesses of
multimodal LLMs/image-editing models and improving the reliability and interpretability of
LLMs.
This work led to me becoming an Auburn Undergraduate Research Fellow and receiving an
honorable mention for the Outstanding Undergraduate Researcher Award from the Computing Research
Association.
Artificial Intelligence and Machine Learning Intern
Corvid Technologies - Huntsville, ALSummer 2025 intern at the defense contractor Corvid Technologies. I worked on applying deep learning to develop more sophisticated methods to predict how 3D objects affect radar response signals.
Biomechanics Deep Learning Lab Assistant
Sport Biomechanics Lab - Auburn UniversityI have worked as a lab assistant at the Auburn Sport Biomechanics lab since Fall 2024. I created a ResNet based pose estimation model to study how different movements can affect the long-term health of canines.
Other Projects
Wordle - GRPO Agent
Finetuned an open-source LLM and trained with reinforcement learning to improve the model from only being able to complete 0.1% of Wordle games to successfully completing 18% of games.

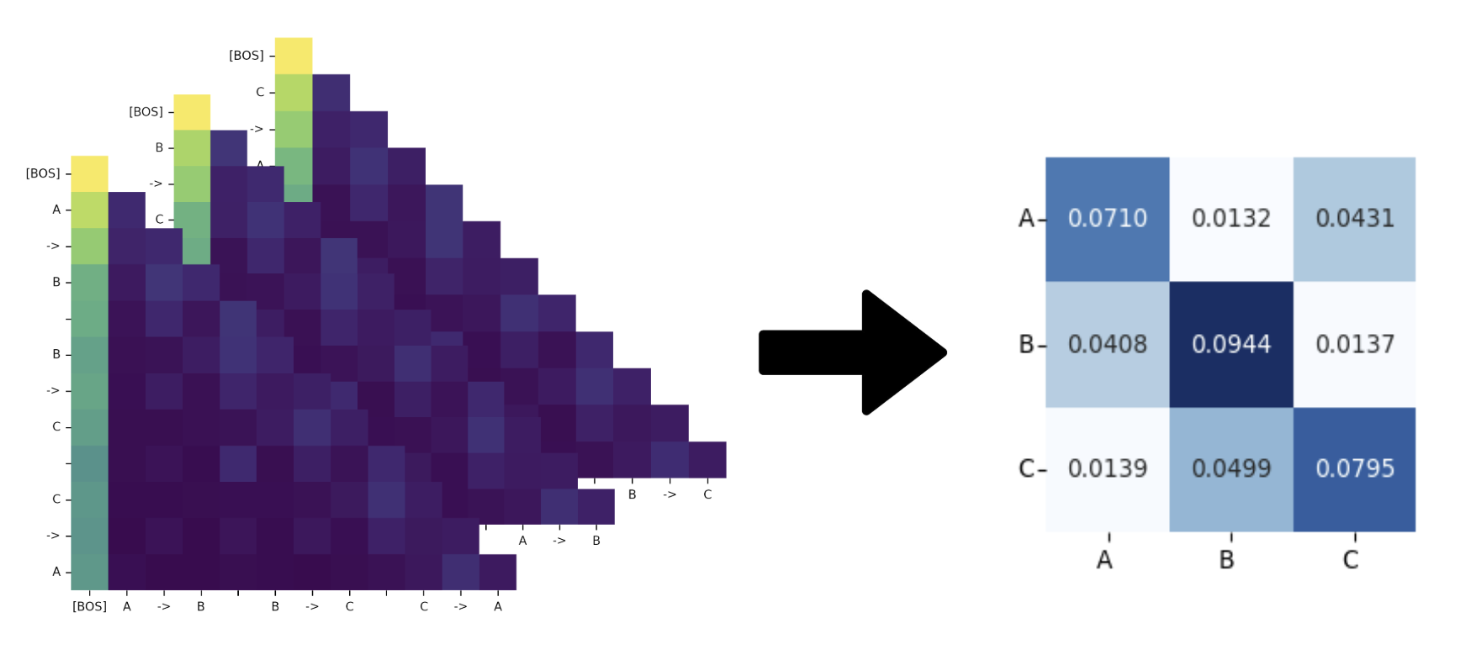
Reverse Engineering Information from LLM Attention Values
For the final project of my graph theory class, I trained a model to reconstruct the adjacency matrix of a graph based off the attention values of an LLM. This project demonstrates an example of how the attention map patterns of LLMs can be used to help interpret the inner workings of language models.
Contact
Have a question or want to work together? Feel free to send me an email:
loganbolton101@gmail.com